Reanimacja w centrum danych
-

- Szymon Pomorski,
- 14.12.2009
Krytycznym aspektem Disaster Recovery jest zdolność do uruchomienia aplikacji biznesowych działających na danych zreplikowanych do ośrodka zapasowego. Posiadanie w lokalizacji zapasowej tylko replik danych, bez pracujących na nich aplikacji, jest bezużyteczne. Dlatego uzupełnieniem technologii replikacji danych do ośrodka zapasowego są rozwiązania klastrowe.
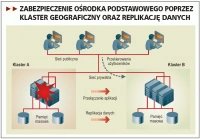
Zabezpieczenie ośrodka podstawowego poprzez klaster geograficzny oraz replikację danych
Tańszym rozwiązaniem, które również można wykorzystać z technologią replikacji do zabezpieczenia danych, jest dysponowanie w lokalizacji zapasowej odpowiednio przygotowanymi serwerami, z zainstalowanymi najnowszymi wersjami oraz poprawkami systemów operacyjnych i aplikacji w stosunku do lokalizacji podstawowej. Często wykorzystywana jest tu powszechnie goszcząca w centrach danych technologia wirtualizacji serwerów.
Centrum danych gotowe na wszystko?
Po ukończeniu wszystkich etapów pośrednich (analiza krytycznych procesów, ustalenie współczynników RTO i RPO, wybór metod zabezpieczenia poszczególnych klas danych), przychodzi czas na dokładne opisanie procedur postępowania dla poszczególnych systemów IT odpowiedzialnych za przebieg procesów biznesowych organizacji.
Ważne jest, aby tworzony dokument miał jasną i przejrzystą strukturę, był kompletny, a więc obejmował wszelkie wymagane odwołania i załączniki oraz aktualizowaną na bieżąco historię zmian. Każdy etap postępowania powinien być jasno zdefiniowany i wyraźnie określać, kiedy możliwe staje się przejście do kolejnego. Po przygotowaniu dokumentu, powinien on zostać rozesłany do członków zespołu ds. sytuacji kryzysowych oraz zapisany w kilku kopiach na różnych nośnikach (np. klucz USB czy składowanie off-site).